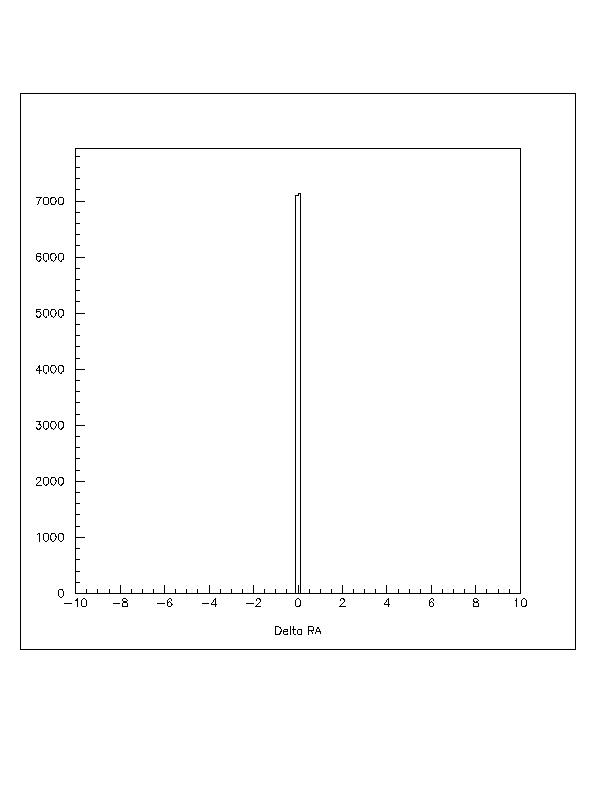
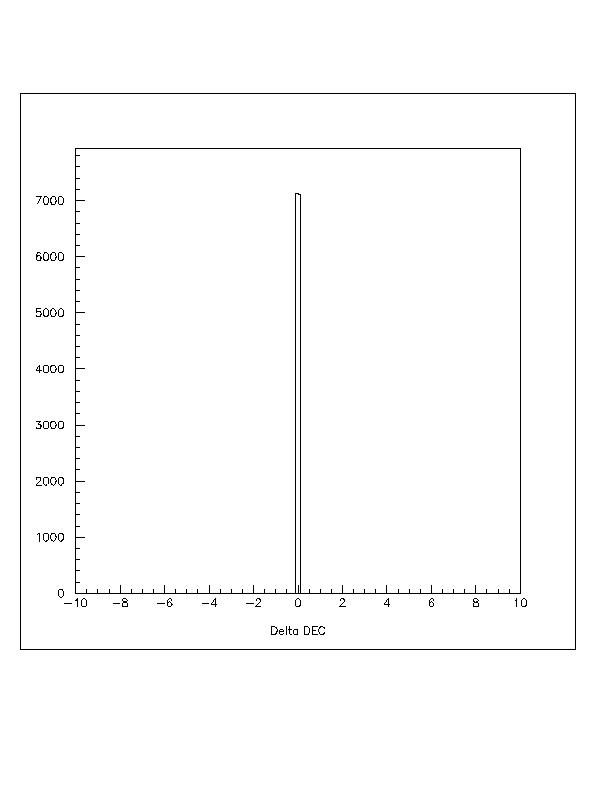
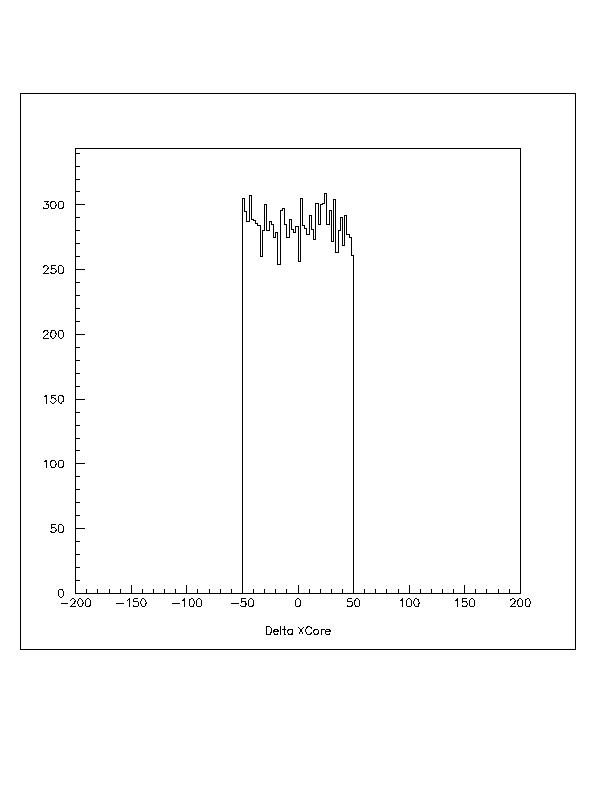
For the first test, the data was reconstructed and compressed online, saved to disk, then decompressed and reconstructed offline on both SGI and Linux platforms. The online and offline reconstructions can then be compared on an event by event basis. The basic battery of tests was developed by Gus Sinnis and has been used to test the current compression scheme. The most interesting graphs are comparing the reconstructed right ascension (RA), declination (DEC) and the core position. Figures representing these measurements are appended to the end of this memo. Note that the .5m scatter on the core reconstruction is because the position from the online reconstruction is only saved to 1m accuracy. The other figures look the same for the variable word length compression and the current compression. The other figures can be found in the .hbook files at milagro.lanl.gov:~mmorales/pub/.
For the second test, after the online Workers compress an event using the information in rawData, they decompress the event into a second rawData structure and compare all of the entries. After running this test for more than a complete subrun, no errors were detected. Since a compress-decompress-compare cycle takes a lot of time, this test was performed with a higher tube threshold than normal (~160 tubes). Still, this test is extremely sensitive to any compression errors, and the ability to perfectly recreate the raw data demonstrates that the variable word length compression is lossless.
Now for a few caveats about the behavior of the new compression scheme. Certain types of information may be discarded, and there are specific requirements that must be met for compression to be successful. There are several types of non-physical values that will not be compressed. For example, in previous versions of the online some edges would have values greater than 3000 counts. Since 3000 is the highest value allowable by our TDCs and headroom is expensive, these tubes were discarded in the compression. This problem has disappeared in version 41 of the online, but problems like it could reappear. These errors are logged by the compression routine. The compression also requires that the tubes be in numerical sequence in the rawData structure. The shrouded tube (#900) is nearly always out of sequence, so the compression has been hardwired to ignore this tube. Consequently tube 900 does not appear in the decompressed data. On occasion an event will contain other out of sequence tubes, and the old compression scheme will be used for that event. The online is designed to keep the tubes in numerical sequence, so the occurrence of this error is not understood. Currently ~1 event per subrun will contain out of sequence tubes, but no data is lost since the old compression is used in these cases. The new compression scheme will compress ADC information. However, since the ADCs are not currently in use, this section of the compression has not been proven.
Please feel free to comment on the behavior and assumptions I've made, and thank you for your time,
-Miguel F. Morales
Below are the figures for the comparison of the online
and offline reconstructions. The angles are measured in degrees and
the core position in centimeters.